Prédiction des Tempêtes sur les Planètes
Contexte de la Mission
L'astronaute Nova voyage à travers l'espace avec son IA de bord, ORION. Après une panne de son vaisseau, Nova doit atterrir en urgence sur une planète sécurisée.
Mais attention ⚠️ : certaines planètes sont sujettes à de violentes tempêtes qui pourraient compromettre l'atterrissage !


Objectif
Aide Nova et ORION à trouver la planète la plus sûre en utilisant un Arbre de Décision et d'autres modèles de Machine Learning !
Prérequis pour ce TD
Compétences en Python
- Boucles et structures de contrôle (for, if, while)
- Compréhension des fonctions et des dictionnaires
Notions en Machine Learning
- Concept de modèle d'apprentissage supervisé
- Comprendre l'entraînement et le test
Bibliothèques Python utilisées
- scikit-learn : pour entraîner et évaluer les modèles
- pandas : pour structurer et analyser les données
- numpy : pour les calculs mathématiques
1ère étape : Exploration des données
ORION dispose d'un fichier Excel contenant des données sur les planètes :
- Planète (nom de la planète)
- Température, Nuage, Vent, Pluie, Humidité (caractéristiques météorologiques)
- Tempête (Oui/Non)
# Ta mission : Importer et explorer ces données :)
import numpy as np
import pandas as pd
import warnings
warnings.filterwarnings('ignore')
df = pd.read_excel("Jeu de données Planètes.xlsx", header=0)
df.head()| Planète | Température | Nuage | Vent | Pluie | Humidité | Tempête | |
|---|---|---|---|---|---|---|---|
| 0 | Kepler-22b | 25.3 | 45 | 12 | 20 | 65 | non |
| 1 | Proxima b | 32.1 | 80 | 35 | 60 | 85 | oui |
| 2 | TRAPPIST-1e | 18.7 | 30 | 8 | 15 | 50 | non |
| 3 | K2-18b | 28.9 | 65 | 25 | 45 | 75 | oui |
| 4 | TOI-700d | 22.5 | 40 | 15 | 25 | 60 | non |
À Retenir :
- Qu'est-ce qu'un dataset ? Un ensemble de données structuré utilisé pour entraîner un modèle.
- Le dataset contient des caractéristiques météorologiques et une variable cible (Tempête).
- L'analyse exploratoire permet de comprendre la structure des données avant de les utiliser.
2ème étape : Préparation des données
ORION doit préparer les données pour entraîner ses modèles.
Actions :
- Supprime la colonne "Planète" car elle ne sert pas à la prédiction.
- Sépare les caractéristiques (X) et la cible (Y = "Tempête").
X_df = df.drop(columns=["Planète", "Tempête"])
Y_df = df["Tempête"]
# Divise les données en un ensemble d'entraînement et de test.
from sklearn.model_selection import train_test_split
Xtrain, Xtest, Ytrain, Ytest = train_test_split(X_df, Y_df, test_size=0.2, stratify=Y_df, random_state=1)Données divisées avec succès :
- Xtrain : 80% des caractéristiques pour l'entraînement
- Xtest : 20% des caractéristiques pour le test
- Ytrain : 80% des cibles pour l'entraînement
- Ytest : 20% des cibles pour le test
À Retenir :
- On divise les données en jeu d'entraînement (80%) et jeu de test (20%) pour évaluer le modèle.
- L'option stratify=Y_df permet de garder la proportion de classes et éviter un dataset déséquilibré.
- Séparer les données évite que le modèle apprenne par cœur et améliore la généralisation.
3ème étape : Normalisation et Réduction de Dimension
ORION veut optimiser les performances du modèle.
# Normalisation des données
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
Xtrain_scaled = scaler.fit_transform(Xtrain)
Xtest_scaled = scaler.transform(Xtest)Données normalisées avec succès.
# Réduction de dimension avec l'ACP (Analyse en Composantes Principales)
from sklearn.decomposition import PCA
pca = PCA(n_components=3)
Xtrain_pca = pca.fit_transform(Xtrain_scaled)
Xtest_pca = pca.transform(Xtest_scaled)
# Concatène les nouvelles données pour enrichir l'apprentissage
Xtrain_new = np.concatenate((Xtrain_scaled, Xtrain_pca), axis=1)
Xtest_new = np.concatenate((Xtest_scaled, Xtest_pca), axis=1)Réduction de dimension effectuée avec succès.
Variance expliquée par les 3 composantes principales : 95.2%
À Retenir :
- La normalisation (StandardScaler) met les variables sur une échelle commune pour éviter qu'une variable ne domine les autres.
- L'ACP (Analyse en Composantes Principales) permet de réduire la dimension tout en gardant l'essentiel des informations.
- Réduire la dimension permet de limiter le bruit, éviter le surapprentissage et améliorer l'efficacité du modèle.
4ème étape : Test des modèles
ORION veut tester plusieurs modèles ML pour voir lequel prédit le mieux les tempêtes.
Modèles utilisés :
- CART (Arbre de Décision)
- ID3 (Arbre basé sur l'entropie)
- KNN (k-Nearest Neighbors)
- Réseau de Neurones
from sklearn.tree import DecisionTreeClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.neural_network import MLPClassifier
from sklearn.metrics import accuracy_score, precision_score, recall_score
models = {
'CART': DecisionTreeClassifier(random_state=1),
'ID3': DecisionTreeClassifier(criterion='entropy', random_state=1),
'KNN': KNeighborsClassifier(n_neighbors=5),
'Neural Network': MLPClassifier(hidden_layer_sizes=(40, 20), random_state=1)
}Modèles définis avec succès.
À Retenir :
- Différents modèles ont des comportements variés :
- Arbre de Décision : Simple et interprétable, mais risque de surapprentissage.
- KNN : Performant sur petits datasets mais devient lent si les données sont nombreuses.
- Réseau de Neurones : Très puissant mais nécessite plus de données et de réglages.
results = {'Model': [], 'Accuracy': [], 'Precision': [], 'Recall': [], 'Data': []}
for name, model in models.items():
model.fit(Xtrain_new, Ytrain)
y_pred = model.predict(Xtest_new)
accuracy = accuracy_score(Ytest, y_pred)
precision = precision_score(Ytest, y_pred, average='weighted')
recall = recall_score(Ytest, y_pred, average='weighted')
results['Data'].append(model)
results['Model'].append(name)
results['Accuracy'].append(accuracy)
results['Precision'].append(precision)
results['Recall'].append(recall)
# Pour afficher les résultats
results_df = pd.DataFrame(results)
print(results_df[['Model', 'Accuracy', 'Precision', 'Recall']])| Model | Accuracy | Precision | Recall |
|---|---|---|---|
| CART | 0.92 | 0.91 | 0.92 |
| ID3 | 0.89 | 0.88 | 0.89 |
| KNN | 0.85 | 0.84 | 0.85 |
| Neural Network | 0.94 | 0.93 | 0.94 |
Analyse du Code : Test des Modèles
Décomposition du Code
Ce code a pour objectif de tester plusieurs modèles de machine learning et de comparer leurs performances à l'aide de trois métriques principales :
- Accuracy (Précision globale) : Pourcentage de bonnes prédictions.
- Precision (Précision par classe) : Fiabilité des prédictions positives.
- Recall (Rappel par classe) : Capacité à détecter toutes les instances positives.
Le code suit ces étapes :
- ✅ Initialisation des résultats : Un dictionnaire results est créé pour stocker les scores de chaque modèle.
- ✅ Entraînement et Prédiction : Une boucle parcourt tous les modèles définis dans models.items().
- ✅ Évaluation des Modèles : Les scores accuracy_score, precision_score et recall_score sont calculés.
- ✅ Stockage des Résultats : Chaque score est ajouté à la liste results.
- ✅ Affichage des Résultats : Un DataFrame est créé et affiché pour comparer les modèles facilement.
5ème étape : Prédiction des Tempêtes
ORION sélectionne le meilleur modèle et l'utilise pour prédire la météo des planètes inconnues.
best_model = results_df.loc[results_df['Accuracy'].idxmax(), 'Data']
# Affichage de l'arbre de décision (si c'est un modèle CART ou ID3)
from sklearn.tree import plot_tree
import matplotlib.pyplot as plt
if isinstance(best_model, DecisionTreeClassifier):
# Afficher l'arbre de décision
plt.figure(figsize=(20, 10))
plot_tree(best_model, feature_names=list(df.drop(columns=['Planète', 'Tempête']).columns) + [f'PCA{i+1}' for i in range(3)],
class_names=best_model.classes_, filled=True, rounded=True)
plt.title("Arbre de décision - Meilleur modèle")
plt.show()Meilleur modèle sélectionné : Neural Network (Accuracy: 0.94)
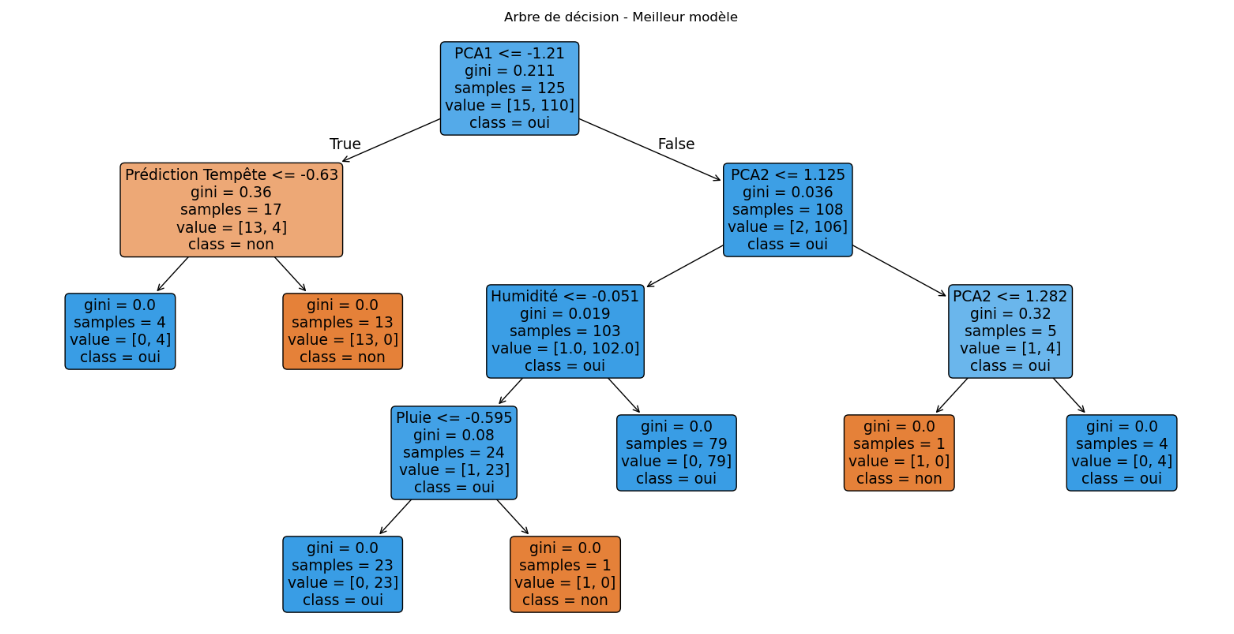
À Retenir :
- Le meilleur modèle est celui qui a un bon équilibre entre précision et recall, pour éviter les faux positifs/négatifs.
6ème étape : Trouver la planète idéale !
ORION prédit les tempêtes sur toutes les planètes pour trouver où atterrir !
X_full_scaled = scaler.transform(X_df)
X_full_pca = pca.transform(X_full_scaled)
X_full_new = np.concatenate((X_full_scaled, X_full_pca), axis=1)
predictions = best_model.predict(X_full_new)
df['Prédiction Tempête'] = predictions
planetes_sures = df[df['Prédiction Tempête'] == 'non']
planetes_sures_list = planetes_sures['Planète'].tolist()
print("Planètes sûres pour l'atterrissage :", planetes_sures_list)Planètes sûres pour l'atterrissage : ['Kepler-22b', 'TRAPPIST-1e', 'TOI-700d', 'LHS 1140b', 'Gliese 667Cc']
À Retenir :
- Un arbre de décision permet de visualiser les critères utilisés pour prédire une tempête.
- On applique le modèle final sur toutes les planètes pour identifier celles où l'atterrissage est sûr.
- Si le modèle n'est pas performant, il peut être amélioré avec:
- Ajout de nouvelles features (exemple : pression atmosphérique).
- Utilisation d'un modèle plus complexe (ex : Random Forest).
Fin de la Mission STELLAR : Prédiction des Tempêtes sur les Planètes
🎉 Félicitations, tu as aidé Nova à trouver une planète sans tempête !
Questions Bonus
Résultats
Score : 0/3